
상속
객체지향 프로그래밍의 장점 중 하나는 코드를 재사용하기가 용이하다는 점이다.
전통적인 패러다임에서는 코드를 복사 후 붙여넣기 하고 수정하여 코드를 재사용하였다.
객체지향에서는 코드를 재사용하기 위해 새로운 코드를 추가한다.
재사용 관점에서 상속이란 클래스 안에 정의된 인스턴스 변수와 메서드를 자동으로 새로운 클래스에 추가하는 구현 기법이다.
상속과 중복 코드
객체지향 프로그래밍을 배울때 부터 기본적으로 중복 코드는 제거해야한다고 배우고 시작한다.
그렇기 때문에 습관적으로 중복코드가 보이면 하나로 합치는 작업을 하게된다.
상속을 이용해 코드를 재사용하기 위해서는 부모 클래스의 개발자가 세웠던 가정이나 추론 과정을 정확하게 이해해야 한다.
이것은 자식 클래스의 작성자가 부모 클래스의 구현 방법에 대한 정확한 지식을 가져야 한다는 것을 의미한다.
따라서 상속은 결합도를 높이며, 이 높은 결합도로 인해 코드를 수정하기 어렵게 만든다.
상속을 위한 경고1
자식 클래스의 메서드 안에서 super 참조를 이용해 부모 클래스의 메서드를 직접 호출할 경우 두 클래스는 강하게 결합된다.
super 호출을 제거할 수 있는 방법을 찾아 결합도를 제거하라.
Dry 원칙
신뢰할 수 있고 수정하기 쉬운 소프트웨어를 만드는 효과적인 방법 중 하나는 중복을 제거하는 것이다.
따라서 프로그래머들은 DRY 원칙을 따라야 한다.
Dry 원칙이란, 반복하지 마라 라는 뜻의 Don’t Refeat Yourself의 첫 글자를 모아 만든 용어로 동일한 지식을 중복하지 말라는 것이다.
Dry 원칙은 한 번, 단 한번 (Once and Only Once) 원칙 또는 단일 지점 제어 (Single-Point Control) 원칙이라고 부른다.
원칙의 이름이 무엇이건, 코드 안에 중복이 존재해서는 안 된다는 것이다.
중복을 제거해야하는 이유
중복 코드는 변경을 방해한다. 이것이 중복 코드를 제거해야 하는 가장 큰 이유다.
중복 코드가 가지는 가장 큰 문제는 코드를 수정하는 데 필요한 노력을 몇 배로 증가시킨다는 것이다.
- 우선 어떤 코드가 중복 코드인지 찾아야 한다
- 중복 코드를 찾았으면 모든 코드를 일관되게 수정해야 한다.
- 모든 중복 코드를 개별적으로 테스트 해서 동일한 결과가 나오는지 확인해야 한다.
이런 작업들 때문에 중복 코드는 수정과 테스트에 드는 비용을 증가시킬뿐만 아니라 개발자를 힘들게 만든다.
어떤 코드가 중복 코드인가?
중복 여부를 판단하는 기준은 변경이다.
요구사항이 변경됐을 때 두 코드를 함께 수정해야 한다면 이 코드는 중복이다. (함께 수정할 필요가 없다면 중복이 아니다.)
중복 코드를 결정하는 기준은 코드의 모양이 아니다. (유사하다는 것은 단지 중복의 징후일 뿐이다.)
취약한 기반 클래스 문제
자식 클래스는 부모 클래스의 불필요한 세부사항에 엮이게 된다.
부모 클래스의 작은 변경에도 자식 클래스는 컴파일 오류와 실행 에러라는 고통에 시달려야 할 수도 있다.
이처럼 부모 클래스의 변경에 의해 자식 클래스가 영향을 받는 현상을 취약한 기반 클래스 문제 라고 부른다.
상속을 사용한다면 피할 수 없는 객체지향 프로그래밍의 근본적인 취약성이다.
높은 결합도
취약한 기반 클래스 문제는 상속이라는 문맥 안에서 결합도가 초래하는 문제점을 가리키는 용어다.
상속 관계를 추가할수록 전체 시스템의 결합도가 높아진다는 사실을 알고 있어야 한다.
상속은 자식 클래스를 점진적으로 추가해서 기능을 확장하는 데는 용이하지만 높은 결합도로 인해 부모 클래스를 점진적으로 개선하는 것은 어렵게 만든다.
캡슐화 약화
취약한 기반 클래스 문제는 캡슐화를 약화시키고 결합도를 높인다.
상속은 자식 클래스가 부모 클래스의 구현 세부사항에 의존하도록 만들기 때문에 캡슐화를 약화시킨다.
객체를 사용하는 이유는 구현과 관련된 세부사항을 퍼블릭 인터페이스 뒤로 캡슐화할 수 있기 때문이다.
캡슐화는 변경에 의한 파급효과를 제어할 수 있기 때문에 가치가 있다.
객체는 변경될지도 모르는 불안정한 요소를 캡슐화함으로써 파급효과를 걱정하지 않고도 자유롭게 내부를 변경할 수 있다.
상속을 이용하면 부모 클래스의 퍼블릭 인터페이스가 아닌 구현을 변경하더라도 자식 클래스가 영향을 받기 쉬워진다.
상속 계층의 상위에 위치한 클래스에 가해지는 작은 변경만으로도 상속 계층에 속한 모든 자손들이 급격하게 요동칠 수 있다.
불필요한 인터페이스 상속 문제
자바 초기 버전에서 상속을 잘못 사용한 대표적인 사례는 두 가지가 있다.
- java.util.Properties
- java.util.Stack
위의 두 클래스의 공통점은 부모 클래스에서 상속받은 메서드를 사용할 경우 자식 클래스의 규칙이 위반될 수 있다는 것이다.
Stack의 문제점
Stack은 가장 나중에 추가된 요소가 가장 먼저 추출되는 (Last In First Out, LIFO) 자료 구조인 스택을 구현한 클래스다.
Vector는 임의의 위치에서 요소를 추출하고 삽입할 수 있는 리스트 자료 구조의 구현체로서 java.util.List의 초기버전이라고 할 수 있다.
자바의 초기 컬렉션 프레임워크 개발자들은 요소의 추가, 삭제 오퍼레이션을 제공하는 Vector를 재사용하기 위해 Stack을 Vector의 자식 클래스로 구현했다.
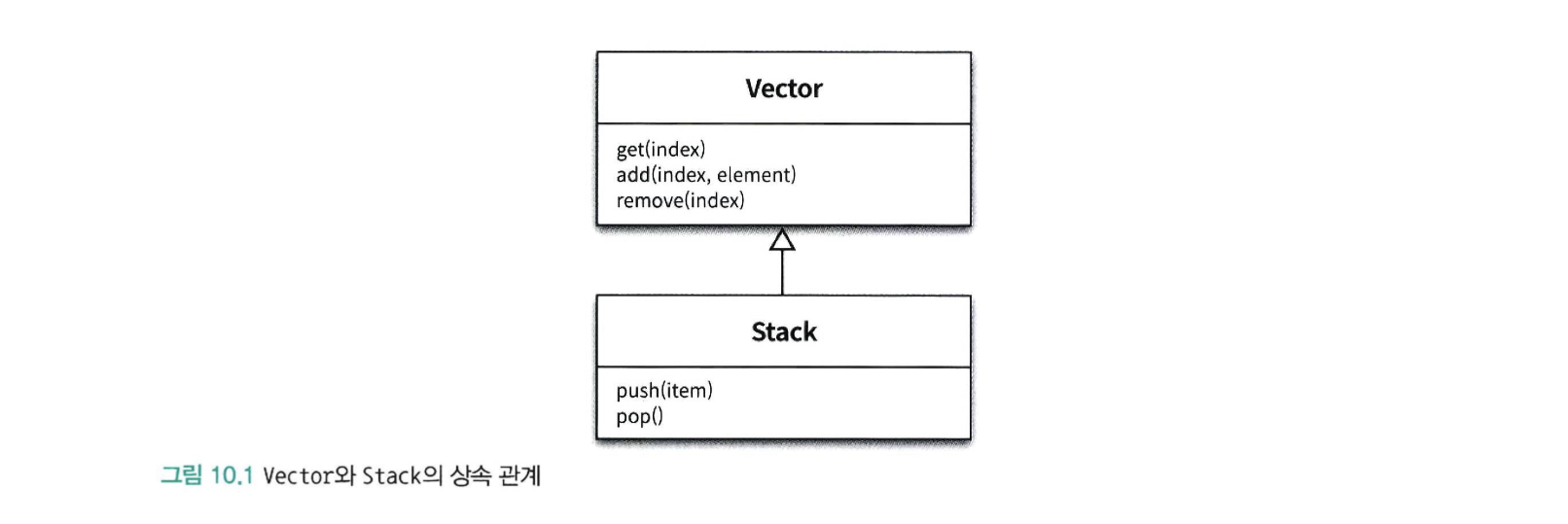
그림 10.1의 퍼블릭 인터페이스를 살펴보면 이 상속 관계가 가지는 문제점을 잘 알 수 있다.
Vector는 임의의 위치(index)에서 요소를 조회하고, 추가하고, 삭제할 수 있는 get, add, remove 오퍼레이션을 제공한다.
이에 비해 Stack은 맨 마지막 위치에서만 요소를 추가하거나 제거할 수 있는 push, pop 오퍼레이션을 제공한다.
Stack은 Vector를 상속받기 때문에 Stack의 퍼블릭 인터페이스에 Vector의 퍼블릭 인터페이스가 합쳐진다.
따라서 Stack에게 상속된 Vector의 퍼블릭 인터페이스를 이용하면 임의의 위치에서 요소를 추가하거나 삭제할 수 있다.
따라서 맨 마지막 위치에서만 요소를 추가하거나 제거할 수 있도록 허용하는 Stack의 규칙을 쉽게 위반할 수 있다.
1 | Stack<String> stack = new Stack<>(); |
위 코드에서 Stack에 마지막으로 추가한 값은 4th이지만 pop 메서드의 반환값은 3rd이다.
그 이유는 Vector의 add 메서드를 이용해서 스택의 맨 앞에 4th를 추가했기 때문이다.
Stack의 예는 퍼블릭 인터페이스에 대한 고려 없이 단순히 코드 재사용을 위해 상속을 이용하는 것이 얼마나 위험한지를 잘 보여준다.
객체지향의 핵심은 객체들의 협력이다.
단순히 코드를 재사용하기 위해 오퍼레이션이 인터페이스에 스며들도록 방치해서는 안 된다.
상속을 위한 경고2
상속받은 부모 클래스의 메서드가 자식 클래스의 내부 구조에 대한 규칙을 깨트릴 수 있다.
메서드 오버라이딩의 부작용 문제
이펙티브 자바에서 HashSet의 구현에 강하게 결합된 InstrumentedHashSet 클래스를 소개한다.
InstrumentedHashSet은 HashSet의 내부에 저장된 요소의 수를 셀 수 있는 기능을 추가한 클래스로서 HashSet의 자식 클래스로 구현돼 있다.
1 | public class InstrumentedHashSet<E> extends HashSet<E> { |
여기서 아래의 코드를 실행했을때 결과를 예측해보자
1 | InstrumentedHashSet<String> languages = new InstrumentedHashSet<>(); |
눈에 보이는 코드만 보면 결과는 3 이라고 예상된다.
하지만 실제 결과는 6이다. 왜 6이 리턴되었을까?
사실은 HashSet의 addAll 메서드에서 add 메서드를 호출하기 때문이다.
부모클래스의 구현을 자세히 알지 못한 채 사용했기 때문에 예상과 다르게 동작한 것이다.
이 문제를 해결하기 위해 InstrumentedHashSet 클래스의 addAll 메서드를 제거할 수 있다.
이러면 컬렉션을 파라미터로 전달하는 경우에는 자동으로 HashSet의 addAll 메서드가 호출되고 내부적으로 추가하려는 각 요소에 대해 InstrumentedHashSet의 add 메서드가 호출되어 예상했던 결과가 나올 것이다.
이 방법 또한 문제가 될 수 있는데 나중에 HashSet의 addAll 메서드가 add 메시지를 전송하지 않도록 수정된다면 addAll 메서드를 이용해 추가되는 요소들에 대한 카운트가 누락될 것이기 때문이다.
이를 해결하기 위한 가장 좋은 방법은 addAll 메서드를 오버라이딩하고 추가되는 각 요소에 대해 한번씩 add 메세지를 호출하는 것이다.
1 | public class InstrumentedHashSet<E> extends HashSet<E> { |
하지만 위의 방법도 문제가 없는 것은 아니다.
바로 오버라이딩 된 addAll 메서드의 구현이 HashSet의 것과 동일하다는 것이다.
즉, 미래에 발생할지 모르는 위험을 방지하기 위해 코드를 중복시킨 것이다.
상속을 위한 경고3
자식 클래스가 부모 클래스의 메서드를 오버라이딩할 경우 부모 클래스가 자신의 메서드를 사용하는 방법에 자식 클래스가 결합될 수 있다.
이펙티브 자바에서는 상속을 할 경우에는 상속을 위해 클래스를 설계하고 문서화해야 하며, 그렇지 않은 경우에는 상속을 금지해야 한다고 한다.
부모 클래스와 자식 클래스의 동시 수정 문제
자식 클래스가 부모 클래스의 메서드를 오버라이딩하거나 불필요한 인터페이스를 상속받지 않았음에도
부모 클래스를 수정할 때 자식 클래스를 함께 수정해야 할 수도 있다는 사실을 잘 보여준다.
상속을 사용하면 자식 클래스가 부모 클래스의 구현에 강하게 결합되기 때문에 이 문제를 피하기는 어렵다.
부모 클래스와 자식 클래스 간의 결합도가 높기 때문에 코드를 함께 수정해야 하는 상황 역시 빈번하게 발생할 수 밖에 없는 것이다.
서브클래스는 올바른 기능을 위해 슈퍼클래스의 세부적인 구현에 의존한다.
슈퍼클래스의 구현은 릴리스를 거치면서 변경될 수 있고, 그에 따라 서브클래스의 코드를 변경하지 않더라도 깨질 수 있다.
결과적으로, 슈퍼클래스의 작성자가 확장될 목적으로 특별히 그 클래스를 설계하지 않았다면 서브클래스는 슈퍼클래스와 보조를 맞춰서 진화해야 한다.
상속을 위한 경고 4
클래스를 상속하면 결합도로 인해 자식 클래스와 부모 클래스의 구현을 영원히 변경하지 않거나, 자식 클래스와 부모 클래스를 동시에 변경하거나 둘 중 하나를 선택할 수밖에 없다.
추상화에 의존된 코드를 작성하라
자식 클래스는 부모 클래스에 강하게 결합되기 때문에 부모 클래스가 변경될 경우 함께 변경될 가능성이 높다.
이 문제를 해결하는 가장 일반적인 방법은 자식 클래스가 부모 클래스의 구현이 아닌 추상화에 의존하도록 만드는 것이다.
정확하게 말해서 부모 클래스와 자식 클래스 모두 추상화에 의존하도록 수정해야 한다.
코드 중복을 제거하기 위해 상속을 도입할 때 따르는 두 가지 원칙이 있다.
- 두 메서드가 유사하게 보인다면 차이점을 메서드로 추출하라. 메세드 추출을 통해 동일한 형태로 보이도록 만들 수 있다.
흔히 말하는 “변하는 것으로 부터 변하지 않는 것을 분리하라” “변하는 부분을 찾고 이를 캡슐화하라” 라는 조언을 메서드 수준에서 적용한 것이다. - 부모 클래스의 코드를 하위로 내리지 말고 자식 클래스의 코드를 상위로 올려라.
부모 클래스의 구체적인 메서드를 자식 클래스로 내리는 것보다 자식 클래스의 추상적인 메서드를 부모 클래스로 올리는 것이 재사용성과 응집도 측면에서 더 뛰어난 결과를 얻을 수 있다.
추상화가 핵심이다
추상화의 장점
- 공통 코드를 이동시킨 후에 각 클래스는 서로 다른 변경의 이유를 가진다는 것에 주목하라.
이런 클래스는 단일 책임의 원칙을 준수하기 때문에 응집도가 높다. - 부모 클래스 역시 자신의 내부에 구현된 추상 메서드를 호출 하기 때문에 추상화에 의존한다고 말할 수 있다.
- 새로운 자식 클래스를 추가하기 쉬운 구조가 된다. 추상 클래스 내의 추상 메서드만 구현하면 되기 때문이다.
- 새로운 자식 클래스가 추가되도 다른 클래스를 수정할 필요가 없다
현재의 설계는 확장에는 열려 있고 수정에는 닫혀 있기 때문에 개방-폐쇄 원칙 역시 준수한다.
차이에 의한 프로그래밍
상속을 사용하면 이미 존재하는 클래스의 코드를 기반으로 다른 부분을 구현함으로써 새로운 기능을 쉽고 빠르게 추가할 수 있다.
상속이 강력한 이유는 익숙한 개념을 이용해서 새로운 개념을 쉽고 빠르게 추가할 수 있기 때문이다.
이처럼 기존 코드와 다른 부분만을 추가함으로써 애플리케이션의 기능을 확장하는 방법을 차이에 의한 프로그래밍(programming by difference) 이라고 부른다.
차이에 의한 프로그래밍의 목표는 중복 코드를 제거하고 코드를 재사용하는 것이다.
사실 중복 제거와 코드 재사용은 동일한 행동을 가리키는 서로 다른 단어다.
중복을 제거하기 위해서는 코드를 재사용 가능한 단위로 분해하고 재구성해야 한다.
코드를 재사용하기 위해서는 중복 코드를 제거해서 하나의 모듈로 모아야 한다.
참고
- Objects(코드로 이해하는 객체지향 설계) - chapter10. 유연한 설계